Event Bus是Vert.x的“神经系统”,是最为关键的几个部分之一。今天我们就来探索一下Event Bus的实现原理。本篇分析的是Local模式的Event Bus,对应的Vert.x版本为3.3.2 。
本文假定读者有一定的并发编程基础以及Vert.x使用基础,并且对Vert.x的线程模型以及back-pressure 有所了解。
Local Event Bus的创建 一般情况下,我们通过Vertx的eventBus方法来创建或获取一个EventBus实例:
1
2
Vertx vertx = Vertx.vertx();
EventBus eventBus = vertx.eventBus();
eventBus方法定义于Vertx接口中,我们来看一下其位于VertxImpl类中的实现:
1
2
3
4
5
6
7
8
9
10
public EventBus eventBus ()
if (eventBus == null ) {
synchronized (this ) {
return eventBus;
}
}
return eventBus;
}
可以看到此方法返回VertxImpl实例中的eventBus成员,同时需要注意并发可见性问题。那么eventBus成员是何时初始化的呢?答案在VertxImpl类的构造函数中。这里截取相关逻辑:
1
2
3
4
5
6
if (options.isClustered()) {
} else {
this .clusterManager = null ;
createAndStartEventBus(options, resultHandler);
}
可以看到VertxImpl内部是通过createAndStartEventBus方法来初始化eventBus的。我们来看一下其逻辑:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
private void createAndStartEventBus (VertxOptions options, Handler<AsyncResult<Vertx>> resultHandler)
if (options.isClustered()) {
eventBus = new ClusteredEventBus(this , options, clusterManager, haManager);
} else {
eventBus = new EventBusImpl(this );
}
eventBus.start(ar2 -> {
if (ar2.succeeded()) {
metrics.eventBusInitialized(eventBus);
if (resultHandler != null ) {
resultHandler.handle(Future.succeededFuture(this ));
}
} else {
log.error("Failed to start event bus" , ar2.cause());
}
});
}
可以看到此方法通过eventBus = new EventBusImpl(this)将eventBus进行了初始化(Local模式为EventBusImpl),并且调用eventBus的start方法对其进行一些额外的初始化工作。我们来看一下EventBusImpl类的start方法:
1
2
3
4
5
6
7
public synchronized void start (Handler<AsyncResult<Void>> completionHandler)
if (started) {
throw new IllegalStateException("Already started" );
}
started = true ;
completionHandler.handle(Future.succeededFuture());
}
首先初始化过程需要防止race condition,因此方法为synchronized的。该方法仅仅将EventBusImpl类中的一个started标志位设为true来代表Event Bus已启动。注意started标志位为volatile的,这样可以保证其可见性,确保其它线程通过checkStarted方法读到的started结果总是最新的。设置完started标志位后,Vert.x会接着调用传入的completionHandler处理函数,也就是上面我们在createAndStartEventBus方法中看到的 —— 调用metrics成员的eventBusInitialized方法以便Metrics类可以在Event Bus初始化完毕后使用它(不过默认情况下此方法的逻辑为空)。
可以看到初始化过程还是比较简单的,我们接下来先来看看订阅消息 —— consumer方法的逻辑。
consume 我们来看一下consumer方法的逻辑,其原型位于EventBus接口中:
1
2
<T> MessageConsumer<T> consumer (String address) ;
<T> MessageConsumer<T> consumer (String address, Handler<Message<T>> handler) ;
其实现位于EventBusImpl类中:
1
2
3
4
5
6
7
@Override
public <T> MessageConsumer<T> consumer (String address, Handler<Message<T>> handler) {
Objects.requireNonNull(handler, "handler" );
MessageConsumer<T> consumer = consumer(address);
consumer.handler(handler);
return consumer;
}
首先要确保传入的handler不为空,然后Vert.x会调用只接受一个address参数的consumer方法获取对应的MessageConsumer,最后给获取到的MessageConsumer绑定上传入的handler。我们首先来看一下另一个consumer方法的实现:
1
2
3
4
5
6
@Override
public <T> MessageConsumer<T> consumer (String address) {
checkStarted();
Objects.requireNonNull(address, "address" );
return new HandlerRegistration<>(vertx, metrics, this , address, null , false , null , -1 );
}
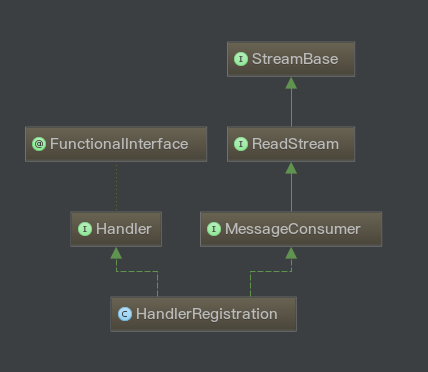
首先Vert.x会检查Event Bus是否已经启动,并且确保传入的地址不为空。然后Vert.x会传入一大堆参数创建一个新的HandlerRegistration类型的实例,并返回。可以推测HandlerRegistration是MessageConsumer接口的具体实现,它一定非常重要。所以我们来看一看HandlerRegistration类是个啥玩意。首先看一下HandlerRegistration的类体系结构:
可以看到HandlerRegistration类同时继承了MessageConsumer<T>以及Handler<Message<T>>接口,从其类名可以看出它相当于一个”Handler注册记录”,是非常重要的一个类。它有一堆的成员变量,构造函数对vertx, metrics, eventBus, address(发送地址), repliedAddress(回复地址), localOnly(是否在集群内传播), asyncResultHandler等几个成员变量进行初始化,并且检查超时时间timeout,如果设定了超时时间那么设定并保存超时计时器(仅用于reply handler中),如果计时器时间到,代表回复超时。因为有一些函数还没介绍,超时的逻辑我们后边再讲。
Note: 由于MessageConsumer接口继承了ReadStream接口,因此它支持back-pressure,其实现就在HandlerRegistration类中。我们将稍后解析back-pressure的实现。
现在回到consumer方法中来。创建了MessageConsumer实例后,我们接着调用它的handler方法绑定上对应的消息处理函数。handler方法的实现位于HandlerRegistration类中:
1
2
3
4
5
6
7
8
9
10
11
12
@Override
public synchronized MessageConsumer<T> handler (Handler<Message<T>> handler)
this .handler = handler;
if (this .handler != null && !registered) {
registered = true ;
eventBus.addRegistration(address, this , repliedAddress != null , localOnly);
} else if (this .handler == null && registered) {
this .unregister();
}
return this ;
}
首先,handler方法将此HandlerRegistration中的handler成员设置为传入的消息处理函数。HandlerRegistration类中有一个registered标志位代表是否已绑定消息处理函数。handler方法会检查传入的handler是否为空且是否已绑定消息处理函数。如果不为空且未绑定,Vert.x就会将registered标志位设为true并且调用eventBus的addRegistration方法将此consumer注册至Event Bus上;如果handler为空且已绑定消息处理函数,我们就调用unregister方法注销当前的consumer。我们稍后会分析unregister方法的实现。
前面提到过注册consumer的逻辑位于Event Bus的addRegistration方法中,因此我们来分析一下它的实现:
1
2
3
4
5
6
protected <T> void addRegistration (String address, HandlerRegistration<T> registration,
boolean replyHandler, boolean localOnly) {
Objects.requireNonNull(registration.getHandler(), "handler" );
boolean newAddress = addLocalRegistration(address, registration, replyHandler, localOnly);
addRegistration(newAddress, address, replyHandler, localOnly, registration::setResult);
}
addRegistration方法接受四个参数:发送地址address、传入的consumer registration、代表是否为reply handler的标志位replyHandler以及代表是否在集群范围内传播的标志位localOnly。首先确保传入的HandlerRegistration不为空。然后Vert.x会调用addLocalRegistration方法将此consumer注册至Event Bus上:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
protected <T> boolean addLocalRegistration (String address, HandlerRegistration<T> registration,
boolean replyHandler, boolean localOnly) {
Objects.requireNonNull(address, "address" );
Context context = Vertx.currentContext();
boolean hasContext = context != null ;
if (!hasContext) {
context = vertx.getOrCreateContext();
}
registration.setHandlerContext(context);
boolean newAddress = false ;
HandlerHolder holder = new HandlerHolder<>(metrics, registration, replyHandler, localOnly, context);
Handlers handlers = handlerMap.get(address);
if (handlers == null ) {
handlers = new Handlers();
Handlers prevHandlers = handlerMap.putIfAbsent(address, handlers);
if (prevHandlers != null ) {
handlers = prevHandlers;
}
newAddress = true ;
}
handlers.list.add(holder);
if (hasContext) {
HandlerEntry entry = new HandlerEntry<>(address, registration);
context.addCloseHook(entry);
}
return newAddress;
}
首先该方法要确保地址address不为空,接着它会获取当前线程下对应的Vert.x Context,如果获取不到则表明当前不在Verticle中(即Embedded),需要调用vertx.getOrCreateContext()来获取Context;然后将获取到的Context赋值给registration内部的handlerContext(代表消息处理对应的Vert.x Context)。
下面就要将给定的registration注册至Event Bus上了。这里Vert.x用一个HandlerHolder类来包装registration和context。接着Vert.x会从存储消息处理Handler的哈希表handlerMap中获取给定地址对应的Handlers,哈希表的类型为ConcurrentMap<String, Handlers>,key为地址,value为对应的HandlerHolder集合。注意这里的Handlers类代表一些Handler的集合,它内部维护着一个列表list用于存储每个HandlerHolder。Handlers类中只有一个choose函数,此函数根据轮询算法从HandlerHolder集合中选定一个HandlerHolder,这即是Event Bus发送消息时实现load-balancing的方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
public class Handlers
private final AtomicInteger pos = new AtomicInteger(0 );
public final List<HandlerHolder> list = new CopyOnWriteArrayList<>();
public HandlerHolder choose ()
while (true ) {
int size = list.size();
if (size == 0 ) {
return null ;
}
int p = pos.getAndIncrement();
if (p >= size - 1 ) {
pos.set(0 );
}
try {
return list.get(p);
} catch (IndexOutOfBoundsException e) {
pos.set(0 );
}
}
}
}
获取到对应的handlers以后,Vert.x首先需要检查其是否为空,如果为空代表此地址还没有注册消息处理Handler,Vert.x就会创建一个Handlers并且将其置入handlerMap中,将newAddress标志位设为true代表这是一个新注册的地址,然后将其赋值给handlers。接着我们向handlers中的HandlerHolder列表list中添加刚刚创建的HandlerHolder实例,这样就将registration注册至Event Bus中了。
前面判断当前线程是否在Vert.x Context的标志位hasContext还有一个用途:如果当前线程在Vert.x Context下(比如在Verticle中),Vert.x会通过addCloseHook方法给当前的context添加一个钩子函数用于注销当前绑定的registration。当对应的Verticle被undeploy的时候,此Verticle绑定的所有消息处理Handler都会被unregister。Hook的类型为HandlerEntry<T>,它继承了Closeable接口,对应的逻辑在close函数中实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
public class HandlerEntry <T > implements Closeable
final String address;
final HandlerRegistration<T> handler;
public HandlerEntry (String address, HandlerRegistration<T> handler)
this .address = address;
this .handler = handler;
}
public void close (Handler<AsyncResult<Void>> completionHandler)
handler.unregister(completionHandler);
completionHandler.handle(Future.succeededFuture());
}
}
可以看到close函数会将绑定的registration从Event Bus的handlerMap中移除并执行completionHandler中的逻辑,completionHandler可由用户指定。
那么在哪里调用这些绑定的hook呢?答案是在DeploymentManager类中的doUndeploy方法中,通过context的runCloseHooks方法执行绑定的hook函数。相关代码如下(只截取相关逻辑):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public synchronized void doUndeploy (ContextImpl undeployingContext, Handler<AsyncResult<Void>> completionHandler)
context.runCloseHooks(ar2 -> {
if (ar2.failed()) {
log.error("Failed to run close hook" , ar2.cause());
}
if (ar.succeeded() && undeployCount.incrementAndGet() == numToUndeploy) {
reportSuccess(null , undeployingContext, completionHandler);
} else if (ar.failed() && !failureReported.get()) {
failureReported.set(true );
reportFailure(ar.cause(), undeployingContext, completionHandler);
}
});
}
再回到addRegistration方法中。刚才addLocalRegistration方法的返回值newAddress代表对应的地址是否为新注册的。接着我们调用另一个版本的addRegistration方法,传入了一大堆参数:
1
2
3
4
5
protected <T> void addRegistration (boolean newAddress, String address,
boolean replyHandler, boolean localOnly,
Handler<AsyncResult<Void>> completionHandler) {
completionHandler.handle(Future.succeededFuture());
}
好吧,传入的前几个参数没用到。。。最后一个参数completionHandler传入的是registration::setResult方法引用,也就是说这个方法调用了对应registration的setResult方法。其实现位于HandlerRegistration类中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
public synchronized void setResult (AsyncResult<Void> result)
this .result = result;
if (completionHandler != null ) {
if (result.succeeded()) {
metric = metrics.handlerRegistered(address, repliedAddress);
}
Handler<AsyncResult<Void>> callback = completionHandler;
vertx.runOnContext(v -> callback.handle(result));
} else if (result.failed()) {
log.error("Failed to propagate registration for handler " + handler + " and address " + address);
} else {
metric = metrics.handlerRegistered(address, repliedAddress);
}
}
首先先设置registration内部的result成员(正常情况下为Future.succeededFuture())。接着Vert.x会判断registration是否绑定了completionHandler(与之前的completionHandler不同,这里的completionHandler是MessageConsumer注册成功时调用的Handler),若绑定则记录Metrics信息(handlerRegistered)并在Vert.x Context内调用completionHandler的逻辑;若未绑定completionHandler则仅记录Metrics信息。
到此为止,consumer方法的逻辑就分析完了。在分析send和publish方法的逻辑之前,我们先来看一下如何注销绑定的MessageConsumer。
unregister 我们通过调用MessageConsumer的unregister方法实现注销操作。Vert.x提供了两个版本的unregister方法:
1
2
3
void unregister ()
void unregister (Handler<AsyncResult<Void>> completionHandler)
其中第二个版本的unregister方法会在注销操作完成时调用传入的completionHandler。比如在cluster范围内注销consumer需要消耗一定的时间在集群内传播,因此第二个版本的方法就会派上用场。我们来看一下其实现,它们最后都是调用了HandlerRegistration类的doUnregister方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
private void doUnregister (Handler<AsyncResult<Void>> completionHandler, boolean callEndHandler)
if (timeoutID != -1 ) {
vertx.cancelTimer(timeoutID);
}
if (endHandler != null && callEndHandler) {
Handler<Void> theEndHandler = endHandler;
Handler<AsyncResult<Void>> handler = completionHandler;
completionHandler = ar -> {
theEndHandler.handle(null );
if (handler != null ) {
handler.handle(ar);
}
};
}
if (registered) {
registered = false ;
eventBus.removeRegistration(address, this , completionHandler);
} else {
callCompletionHandlerAsync(completionHandler);
}
registered = false ;
}
如果设定了超时定时器(timeoutID合法),那么Vert.x会首先将定时器关闭。接着Vert.x会判断是否需要调用endHandler。那么endHandler又是什么呢?前面我们提到过MessageConsumer接口继承了ReadStream接口,而ReadStream接口定义了一个endHandler方法用于绑定一个endHandler,当stream中的数据读取完毕时会调用。而在Event Bus中,消息源源不断地从一处发送至另一处,因此只有在某个consumerdoUnregister方法中调用endHandler。
接着Vert.x会判断此consumer是否已注册消息处理函数Handler(通过检查registered标志位),若已注册则将对应的Handler从Event Bus中的handlerMap中移除并将registered设为false;若还未注册Handler且提供了注销结束时的回调completionHandler(注意不是HandlerRegistration类的成员变量completionHandler,而是之前第二个版本的unregister中传入的Handler,用同样的名字很容易混。。。),则通过callCompletionHandlerAsync方法调用回调函数。
从Event Bus中移除Handler的逻辑位于EventBusImpl类的removeRegistration方法中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
protected <T> void removeRegistration (String address, HandlerRegistration<T> handler, Handler<AsyncResult<Void>> completionHandler)
HandlerHolder holder = removeLocalRegistration(address, handler);
removeRegistration(holder, address, completionHandler);
}
protected <T> void removeRegistration (HandlerHolder handlerHolder, String address,
Handler<AsyncResult<Void>> completionHandler) {
callCompletionHandlerAsync(completionHandler);
}
protected <T> HandlerHolder removeLocalRegistration (String address, HandlerRegistration<T> handler) {
Handlers handlers = handlerMap.get(address);
HandlerHolder lastHolder = null ;
if (handlers != null ) {
synchronized (handlers) {
int size = handlers.list.size();
for (int i = 0 ; i < size; i++) {
HandlerHolder holder = handlers.list.get(i);
if (holder.getHandler() == handler) {
handlers.list.remove(i);
holder.setRemoved();
if (handlers.list.isEmpty()) {
handlerMap.remove(address);
lastHolder = holder;
}
holder.getContext().removeCloseHook(new HandlerEntry<>(address, holder.getHandler()));
break ;
}
}
}
}
return lastHolder;
}
其真正的unregister逻辑位于removeLocalRegistration方法中。首先需要从handlerMap中获取地址对应的Handlers实例handlers,如果handlers不为空,为了防止并发问题,Vert.x需要对其加锁后再进行操作。Vert.x需要遍历handlers中的列表,遇到与传入的HandlerRegistration相匹配的HandlerHolder就将其从列表中移除,然后调用对应holder的setRemoved方法标记其为已注销并记录Metrics数据(handlerUnregistered)。如果移除此HandlerHolder后handlers没有任何注册的Handler了,就将该地址对应的Handlers实例从handlerMap中移除并保存刚刚移除的HandlerHolder。另外,由于已经将此consumer注销,在undeploy verticle的时候不需要再进行unregister,因此这里还要将之前注册到context的hook移除。
调用完removeLocalRegistration方法以后,Vert.x会调用另一个版本的removeRegistration方法,调用completionHandler(用户在第二个版本的unregister方法中传入的处理函数)对应的逻辑,其它的参数都没什么用。。。
这就是MessageConsumer注销的逻辑实现。下面就到了本文的另一重头戏了 —— 发送消息相关的函数send和publish。
send & publish send和publish的逻辑相近,只不过一个是发送至目标地址的某一消费者,一个是发布至目标地址的所有消费者。Vert.x使用一个标志位send来代表是否为点对点发送模式。
几个版本的send和publish最终都归结于生成消息对象然后调用sendOrPubInternal方法执行逻辑,只不过send标志位不同:
1
2
3
4
5
6
7
8
9
10
11
@Override
public <T> EventBus send (String address, Object message, DeliveryOptions options, Handler<AsyncResult<Message<T>>> replyHandler) {
sendOrPubInternal(createMessage(true , address, options.getHeaders(), message, options.getCodecName()), options, replyHandler);
return this ;
}
@Override
public EventBus publish (String address, Object message, DeliveryOptions options)
sendOrPubInternal(createMessage(false , address, options.getHeaders(), message, options.getCodecName()), options, null );
return this ;
}
两个方法中都是通过createMessage方法来生成对应的消息对象的:
1
2
3
4
5
6
7
protected MessageImpl createMessage (boolean send, String address, MultiMap headers, Object body, String codecName)
Objects.requireNonNull(address, "no null address accepted" );
MessageCodec codec = codecManager.lookupCodec(body, codecName);
@SuppressWarnings ("unchecked" )
MessageImpl msg = new MessageImpl(address, null , headers, body, codec, send, this );
return msg;
}
createMessage方法接受5个参数:send即上面提到的标志位,address为发送目标地址,headers为设置的header,body代表发送的对象,codecName代表对应的Codec(消息编码解码器)名称。createMessage方法首先会确保地址不为空,然后通过codecManager来获取对应的MessageCodec。如果没有提供Codec(即codecName为空),那么codecManager会根据发送对象body的类型来提供内置的Codec实现(具体逻辑请见此处 )。准备好MessageCodec后,createMessage方法就会创建一个MessageImpl实例并且返回。
这里我们还需要了解一下MessageImpl的构造函数:
1
2
3
4
5
6
7
8
9
10
11
public MessageImpl (String address, String replyAddress, MultiMap headers, U sentBody,
MessageCodec<U, V> messageCodec,
boolean send, EventBusImpl bus) {
this .messageCodec = messageCodec;
this .address = address;
this .replyAddress = replyAddress;
this .headers = headers;
this .sentBody = sentBody;
this .send = send;
this .bus = bus;
}
createMessage方法并没有设置回复地址replyAddress。如果用户指定了replyHandler的话,后边sendOrPubInternal方法会对此消息实体进行加工,设置replyAddress并生成回复逻辑对应的HandlerRegistration。
我们看一下sendOrPubInternal方法的源码:
1
2
3
4
5
6
7
private <T> void sendOrPubInternal (MessageImpl message, DeliveryOptions options,
Handler<AsyncResult<Message<T>>> replyHandler) {
checkStarted();
HandlerRegistration<T> replyHandlerRegistration = createReplyHandlerRegistration(message, options, replyHandler);
SendContextImpl<T> sendContext = new SendContextImpl<>(message, options, replyHandlerRegistration);
sendContext.next();
}
它接受三个参数:要发送的消息message,发送配置选项options以及回复处理函数replyHandler。首先sendOrPubInternal方法要检查Event Bus是否已启动,接着如果绑定了回复处理函数,Vert.x就会调用createReplyHandlerRegistration方法给消息实体message包装上回复地址,并且生成对应的reply consumer。接着Vert.x创建了一个包装消息的SendContextImpl实例并调用了其next方法。
我们一步一步来解释。首先是createReplyHandlerRegistration方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
private <T> HandlerRegistration<T> createReplyHandlerRegistration (MessageImpl message, DeliveryOptions options, Handler<AsyncResult<Message<T>>> replyHandler) {
if (replyHandler != null ) {
long timeout = options.getSendTimeout();
String replyAddress = generateReplyAddress();
message.setReplyAddress(replyAddress);
Handler<Message<T>> simpleReplyHandler = convertHandler(replyHandler);
HandlerRegistration<T> registration =
new HandlerRegistration<>(vertx, metrics, this , replyAddress, message.address, true , replyHandler, timeout);
registration.handler(simpleReplyHandler);
return registration;
} else {
return null ;
}
}
createReplyHandlerRegistration方法首先检查传入的replyHandler是否为空(是否绑定了replyHandler,回复处理函数),如果为空则代表不需要处理回复,直接返回null;若replyHandler不为空,createReplyHandlerRegistration方法就会从配置中获取reply的最大超时时长(默认30s),然后调用generateReplyAddress方法生成对应的回复地址replyAddress:
1
2
3
4
5
private final AtomicLong replySequence = new AtomicLong(0 );
protected String generateReplyAddress ()
return Long.toString(replySequence.incrementAndGet());
}
生成回复地址的逻辑有点简单。。。。EventBusImpl实例中维护着一个AtomicLong类型的replySequence成员变量代表对应的回复地址。每次生成的时候都会使其自增,然后转化为String。也就是说生成的replyAddress都类似于”1”、”5”这样,而不是我们想象中的直接回复至sender的地址。。。
生成完毕以后,createReplyHandlerRegistration方法会将生成的replyAddress设定到消息对象message中。接着Vert.x会通过convertHandler方法对replyHandler进行包装处理并生成类型简化为Handler<Message<T>>的simpleReplyHandler,它用于绑定至后面创建的reply consumer上。接着Vert.x会创建对应的reply consumer。关于reply操作的实现,我们后边会详细讲述。下面Vert.x就通过handler方法将生成的回复处理函数simpleReplyHandler绑定至创建好的reply consumer中,其底层实现我们之前已经分析过了,这里就不再赘述。最后此方法返回生成的registration,即对应的reply consumer。注意这个reply consumer是一次性 的,也就是说Vert.x会在其接收到回复或超时的时候自动对其进行注销。
OK,现在回到sendOrPubInternal方法中来。下面Vert.x会创建一个SendContextImpl实例并调用其next方法。SendContextImpl类实现了SendContext接口,它相当于一个消息的封装体,并且可以与Event Bus中的interceptors(拦截器)结合使用。
SendContext接口定义了三个方法:
message: 获取当前SendContext包装的消息实体next: 调用下一个消息拦截器send: 代表消息的发送模式是否为点对点模式
在Event Bus中,消息拦截器本质上是一个Handler<SendContext>类型的处理函数。Event Bus内部存储着一个interceptors列表用于存储绑定的消息拦截器。我们可以通过addInterceptor和removeInterceptor方法进行消息拦截器的添加和删除操作。如果要进行链式拦截,则在每个拦截器中都应该调用对应SendContext的next方法,比如:
1
2
3
4
eventBus.addInterceptor(sc -> {
sc.next();
});
我们来看一下SendContextImpl类中next方法的实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
protected class SendContextImpl <T > implements SendContext <T >
public final MessageImpl message;
public final DeliveryOptions options;
public final HandlerRegistration<T> handlerRegistration;
public final Iterator<Handler<SendContext>> iter;
public SendContextImpl (MessageImpl message, DeliveryOptions options, HandlerRegistration<T> handlerRegistration)
this .message = message;
this .options = options;
this .handlerRegistration = handlerRegistration;
this .iter = interceptors.iterator();
}
@Override
public Message<T> message ()
return message;
}
@Override
public void next ()
if (iter.hasNext()) {
Handler<SendContext> handler = iter.next();
try {
handler.handle(this );
} catch (Throwable t) {
log.error("Failure in interceptor" , t);
}
} else {
sendOrPub(this );
}
}
@Override
public boolean send ()
return message.send();
}
}
我们可以看到,SendContextImpl类中维护了一个拦截器列表对应的迭代器。每次调用next方法时,如果迭代器中存在拦截器,就将下个拦截器取出并进行相关调用。如果迭代器为空,则代表拦截器都已经调用完毕,Vert.x就会调用EventBusImpl类下的sendOrPub方法进行消息的发送操作。
sendOrPub方法仅仅在metrics模块中记录相关数据(messageSent),最后调用deliverMessageLocally(SendContextImpl<T>)方法执行消息的发送逻辑:
1
2
3
4
5
6
7
8
9
10
protected <T> void deliverMessageLocally (SendContextImpl<T> sendContext)
if (!deliverMessageLocally(sendContext.message)) {
metrics.replyFailure(sendContext.message.address, ReplyFailure.NO_HANDLERS);
if (sendContext.handlerRegistration != null ) {
sendContext.handlerRegistration.sendAsyncResultFailure(ReplyFailure.NO_HANDLERS, "No handlers for address "
+ sendContext.message.address);
}
}
}
这里面又套了一层。。。它最后其实是调用了deliverMessageLocally(MessageImpl)方法。此方法返回值代表发送消息的目标地址是否注册有MessageConsumer,如果没有(false)则记录错误并调用sendContext中保存的回复处理函数处理错误(如果绑定了replyHandler的话)。
deliverMessageLocally(MessageImpl)方法是真正区分send和publish的地方,我们来看一下其实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
protected <T> boolean deliverMessageLocally (MessageImpl msg)
msg.setBus(this );
Handlers handlers = handlerMap.get(msg.address());
if (handlers != null ) {
if (msg.send()) {
HandlerHolder holder = handlers.choose();
metrics.messageReceived(msg.address(), !msg.send(), isMessageLocal(msg), holder != null ? 1 : 0 );
if (holder != null ) {
deliverToHandler(msg, holder);
}
} else {
metrics.messageReceived(msg.address(), !msg.send(), isMessageLocal(msg), handlers.list.size());
for (HandlerHolder holder: handlers.list) {
deliverToHandler(msg, holder);
}
}
return true ;
} else {
metrics.messageReceived(msg.address(), !msg.send(), isMessageLocal(msg), 0 );
return false ;
}
}
首先Vert.x需要从handlerMap中获取目标地址对应的处理函数集合handlers。接着,如果handlers不为空的话,Vert.x就会判断消息实体的send标志位。如果send标志位为true则代表以点对点模式发送,Vert.x就会通过handlers的choose方法(之前提到过),按照轮询算法来获取其中的某一个HandlerHolder。获取到HandlerHolder之后,Vert.x会通过deliverToHandler方法将消息分发至HandlerHolder中进行处理;如果send标志位为false则代表向所有消费者发布消息,Vert.x就会对handlers中的每一个HandlerHolder依次调用deliverToHandler方法,以便将消息分发至所有注册到此地址的Handler中进行处理。
消息处理的真正逻辑就在deliverToHandler方法中。我们来看一下它的源码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
private <T> void deliverToHandler (MessageImpl msg, HandlerHolder<T> holder)
@SuppressWarnings ("unchecked" )
Message<T> copied = msg.copyBeforeReceive();
if (metrics.isEnabled()) {
metrics.scheduleMessage(holder.getHandler().getMetric(), msg.isLocal());
}
holder.getContext().runOnContext((v) -> {
try {
if (!holder.isRemoved()) {
holder.getHandler().handle(copied);
}
} finally {
if (holder.isReplyHandler()) {
holder.getHandler().unregister();
}
}
});
}
首先deliverToHandler方法会复制一份要发送的消息,然后deliverToHandler方法会调用metrics的scheduleMessage方法记录对应的Metrics信息(计划对消息进行处理。此函数修复了Issue 1480 )。接着deliverToHandler方法会从传入的HandlerHolder中获取对应的Vert.x Context,然后调用runOnContext方法以便可以让消息处理逻辑在Vert.x Context中执行。为防止对应的handler在处理之前被移除,这里还需要检查一下holder的isRemoved属性。如果没有移除,那么就从holder中获取对应的handler并调用其handle方法执行消息的处理逻辑。注意这里获取的handler实际上是一个HandlerRegistration。前面提到过HandlerRegistration类同时实现了MessageConsumer接口和Handler接口,因此它兼具这两个接口所期望的功能。另外,之前我们提到过Vert.x会自动注销接收过回复的reply consumer,其逻辑就在这个finally块中。Vert.x会检查holder中的handler是否为reply handler(reply consumer),如果是的话就调用其unregister方法将其注销,来确保reply consumer为一次性的。
之前我们提到过MessageConsumer继承了ReadStream接口,因此HandlerRegistration需要实现flow control(back-pressure)的相关逻辑。那么如何实现呢?我们看到,HandlerRegistration类中有一个paused标志位代表是否还继续处理消息。ReadStream接口中定义了两个函数用于控制stream的通断:当处理速度小于读取速度(发生拥塞)的时候我们可以通过pause方法暂停消息的传递,将积压的消息暂存于内部的消息队列(缓冲区)pending中;当相对速度正常的时候,我们可以通过resume方法恢复消息的传递和处理。
我们看一下HandlerRegistration中handle方法的实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
@Override
public void handle (Message<T> message)
Handler<Message<T>> theHandler;
synchronized (this ) {
if (paused) {
if (pending.size() < maxBufferedMessages) {
pending.add(message);
} else {
if (discardHandler != null ) {
discardHandler.handle(message);
} else {
log.warn("Discarding message as more than " + maxBufferedMessages + " buffered in paused consumer" );
}
}
return ;
} else {
if (pending.size() > 0 ) {
pending.add(message);
message = pending.poll();
}
theHandler = handler;
}
}
deliver(theHandler, message);
}
果然。。。handle方法在处理消息的基础上实现了拥塞控制的功能。为了防止资源争用,需要对自身进行加锁;首先handle方法会判断当前的consumer是否为paused状态,如果为paused状态,handle方法会检查当前缓冲区大小是否已经超过给定的最大缓冲区大小maxBufferedMessages,如果没超过,就将收到的消息push到缓冲区中;如果大于或等于阈值,Vert.x就需要丢弃超出的那部分消息。如果当前的consumer为正常状态,则如果缓冲区不为空,就将收到的消息push到缓冲区中并从缓冲区中pull队列首端的消息,然后调用deliver方法执行真正的消息处理逻辑。注意这里是在锁之外执行deliver方法的,这是为了保证在multithreaded worker context下可以并发传递消息(见Bug 473714
)。由于multithreaded worker context允许在不同线程并发执行逻辑(见官方文档 ),如果将deliver方法置于synchronized块之内,其他线程必须等待当前锁被释放才能进行消息的传递逻辑,因而不能做到“delivery concurrently”。
deliver方法是真正执行“消息处理”逻辑的地方:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
private void deliver (Handler<Message<T>> theHandler, Message<T> message)
checkNextTick();
boolean local = true ;
if (message instanceof ClusteredMessage) {
ClusteredMessage cmsg = (ClusteredMessage)message;
if (cmsg.isFromWire()) {
local = false ;
}
}
String creditsAddress = message.headers().get(MessageProducerImpl.CREDIT_ADDRESS_HEADER_NAME);
if (creditsAddress != null ) {
eventBus.send(creditsAddress, 1 );
}
try {
metrics.beginHandleMessage(metric, local);
theHandler.handle(message);
metrics.endHandleMessage(metric, null );
} catch (Exception e) {
log.error("Failed to handleMessage" , e);
metrics.endHandleMessage(metric, e);
throw e;
}
}
首先Vert.x会调用checkNextTick方法来检查消息队列(缓冲区)中是否存在更多的消息等待被处理,如果有的话就取出队列首端的消息并调用deliver方法将其传递给handler进行处理。这里仍需要注意并发问题,相关实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
private synchronized void checkNextTick ()
if (!pending.isEmpty()) {
handlerContext.runOnContext(v -> {
Message<T> message;
Handler<Message<T>> theHandler;
synchronized (HandlerRegistration.this ) {
if (paused || (message = pending.poll()) == null ) {
return ;
}
theHandler = handler;
}
deliver(theHandler, message);
});
}
}
检查完消息队列以后,Vert.x会接着根据message判断消息是否仅在本地进行处理并给local标志位赋值,local标志位将在记录Metrics数据时用到。
接下来我们看到Vert.x从消息的headers中获取了一个地址creditsAddress,如果creditsAddress存在就向此地址发送一条消息,body为1。那么这个creditsAddress又是啥呢?其实,它与flow control有关,我们会在下面详细分析。发送完credit消息以后,接下来就到了调用handler处理消息的时刻了。在处理消息之前需要调用metrics的beginHandleMessage方法记录消息开始处理的metrics数据,在处理完消息以后需要调用endHandleMessage方法记录消息处理结束的metrics数据。
嗯。。。到此为止,消息的发送和处理过程就已经一目了然了。下面我们讲一讲之前代码中出现的creditsAddress到底是啥玩意~
MessageProducer 之前我们提到过,Vert.x定义了两个接口作为 flow control aware object 的规范:WriteStream以及ReadStream。对于ReadStream我们已经不再陌生了,MessageConsumer就继承了它;那么大家应该可以想象到,有MessageConsumer就必有MessageProducer。不错,Vert.x中的MessageProducer接口对应某个address上的消息生产者,同时它继承了WriteStream接口,因此MessageProducer的实现类MessageProducerImpl同样具有flow control的能力。我们可以把MessageProducer看做是一个具有flow control功能的增强版的EventBus。我们可以通过EventBus接口的publisher方法创建一个MessageProducer。
对MessageProducer有了初步了解之后,我们就可以解释前面deliver方法中的creditsAddress了。MessageProducer接口的实现类 —— MessageProducerImpl类的流量控制功能是基于credit的,其内部会维护一个credit值代表“发送消息的能力”,其默认值等于DEFAULT_WRITE_QUEUE_MAX_SIZE:
1
2
private int maxSize = DEFAULT_WRITE_QUEUE_MAX_SIZE;
private int credits = DEFAULT_WRITE_QUEUE_MAX_SIZE;
在采用点对点模式发送消息的时候,MessageProducer底层会调用doSend方法进行消息的发送。发送依然利用Event Bus的send方法,只不过doSend方法中添加了flow control的相关逻辑:
1
2
3
4
5
6
7
8
9
10
11
12
private synchronized <R> void doSend (T data, Handler<AsyncResult<Message<R>>> replyHandler)
if (credits > 0 ) {
credits--;
if (replyHandler == null ) {
bus.send(address, data, options);
} else {
bus.send(address, data, options, replyHandler);
}
} else {
pending.add(data);
}
}
与MessageConsumer类似,MessageProducer内部同样保存着一个消息队列(缓冲区)用于暂存堆积的消息。当credits大于0 的时候代表可以发送消息(没有出现拥塞),Vert.x就会调用Event Bus的send方法进行消息的发送,同时credits要减1;如果credits小于等于0,则代表此时消息发送的速度太快,出现了拥塞,需要暂缓发送,因此将要发送的对象暂存于缓冲区中。大家可能会问,credits值不断减小,那么恢复消息发送能力(增大credits)的逻辑在哪呢?这就要提到creditsAddress了。我们看一下MessageProducerImpl类的构造函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
public MessageProducerImpl (Vertx vertx, String address, boolean send, DeliveryOptions options)
this .vertx = vertx;
this .bus = vertx.eventBus();
this .address = address;
this .send = send;
this .options = options;
if (send) {
String creditAddress = UUID.randomUUID().toString() + "-credit" ;
creditConsumer = bus.consumer(creditAddress, msg -> {
doReceiveCredit(msg.body());
});
options.addHeader(CREDIT_ADDRESS_HEADER_NAME, creditAddress);
} else {
creditConsumer = null ;
}
}
MessageProducerImpl的构造函数中生成了一个creditAddress,然后给该地址绑定了一个Handler,当收到消息时调用doReceiveCredit方法执行解除拥塞,恢复消息发送的逻辑。MessageProducerImpl会将此MessageConsumer保存,以便在关闭消息生产者流的时候将其注销。接着构造函数会往options的headers中添加一条记录,保存对应的creditAddress,这也就是上面我们在deliver函数中获取的creditAddress:
1
2
3
4
5
String creditsAddress = message.headers().get(MessageProducerImpl.CREDIT_ADDRESS_HEADER_NAME);
if (creditsAddress != null ) {
eventBus.send(creditsAddress, 1 );
}
这样,发送消息到creditsAddress的逻辑也就好理解了。由于deliver函数的逻辑就是处理消息,因此这里向creditsAddress发送一个 1 其实就是将对应的credits值加1。恢复消息发送的逻辑位于MessageProducerImpl类的doReceiveCredit方法中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
private synchronized void doReceiveCredit (int credit)
credits += credit;
while (credits > 0 ) {
T data = pending.poll();
if (data == null ) {
break ;
} else {
credits--;
bus.send(address, data, options);
}
}
final Handler<Void> theDrainHandler = drainHandler;
if (theDrainHandler != null && credits >= maxSize / 2 ) {
this .drainHandler = null ;
vertx.runOnContext(v -> theDrainHandler.handle(null ));
}
}
逻辑一目了然。首先给credits加上发送过来的值(正常情况下为1),然后恢复发送能力,将缓冲区的数据依次取出、发送然后减小credits。同时如果MessageProducer绑定了drainHandler(消息流不拥塞的时候调用的逻辑,详见官方文档 ),并且MessageProducer发送的消息不再拥塞(credits >= maxSize / 2),那么就在Vert.x Context中执行drainHandler中的逻辑。
怎么样,体会到Vert.x中flow control的强大之处了吧!官方文档中MessageProducer的篇幅几乎没有,只在介绍WriteStream的时候提了提,因此这部分也可以作为MessageProducer的参考。
reply 最后就是消息的回复逻辑 —— reply方法了。reply方法的实现位于MessageImpl类中,最终调用的是reply(Object, DeliveryOptions, Handler<AsyncResult<Message<R>>>)这个版本:
1
2
3
4
5
6
@Override
public <R> void reply (Object message, DeliveryOptions options, Handler<AsyncResult<Message<R>>> replyHandler)
if (replyAddress != null ) {
sendReply(bus.createMessage(true , replyAddress, options.getHeaders(), message, options.getCodecName()), options, replyHandler);
}
}
这里reply方法同样调用EventBus的createMessage方法创建要回复的消息实体,传入的replyAddress即为之前讲过的生成的非常简单的回复地址。然后再将消息实体、配置以及对应的replyHandler(如果有的话)传入sendReply方法进行消息的回复。最后其实是调用了Event Bus中的四个参数的sendReply方法,它的逻辑与之前讲过的sendOrPubInternal非常相似:
1
2
3
4
5
6
7
8
9
protected <T> void sendReply (MessageImpl replyMessage, MessageImpl replierMessage, DeliveryOptions options,
Handler<AsyncResult<Message<T>>> replyHandler) {
if (replyMessage.address() == null ) {
throw new IllegalStateException("address not specified" );
} else {
HandlerRegistration<T> replyHandlerRegistration = createReplyHandlerRegistration(replyMessage, options, replyHandler);
new ReplySendContextImpl<>(replyMessage, options, replyHandlerRegistration, replierMessage).next();
}
}
参数中replyMessage代表回复消息实体,replierMessage则代表回复者自身的消息实体(sender)。
如果地址为空则抛出异常;如果地址不为空,则先调用createReplyHandlerRegistration方法创建对应的replyHandlerRegistration。createReplyHandlerRegistration方法的实现之前已经讲过了。注意这里的createReplyHandlerRegistration其实对应的是此replier的回复,因为Vert.x中的 Request-Response 消息模型不限制相互回复(通信)的次数。当然如果没有指定此replier的回复的replyHandler,那么此处的replyHandlerRegistration就为空。最后sendReply方法会创建一个ReplySendContextImpl并调用其next方法。
ReplySendContextImpl类同样是SendContext接口的一个实现(继承了SendContextImpl类)。ReplySendContextImpl比起其父类就多保存了一个replierMessage。next方法的逻辑与父类逻辑非常相似,只不过将回复的逻辑替换成了另一个版本的sendReply方法:
1
2
3
4
5
6
7
8
9
@Override
public void next ()
if (iter.hasNext()) {
Handler<SendContext> handler = iter.next();
handler.handle(this );
} else {
sendReply(this , replierMessage);
}
}
然而。。。sendReply方法并没有用到传入的replierMessage,所以这里最终还是调用了sendOrPub方法(尼玛,封装的ReplySendContextImpl貌似并没有什么卵用,可能为以后的扩展考虑?)。。。之后的逻辑我们都已经分析过了。
这里再强调一点。当我们发送消息同时指定replyHandler的时候,其内部为reply创建的reply consumer(类型为HandlerRegistration)指定了timeout。这个定时器从HandlerRegistration创建的时候就开始计时了。我们回顾一下:
1
2
3
4
5
6
if (timeout != -1 ) {
timeoutID = vertx.setTimer(timeout, tid -> {
metrics.replyFailure(address, ReplyFailure.TIMEOUT);
sendAsyncResultFailure(ReplyFailure.TIMEOUT, "Timed out after waiting " + timeout + "(ms) for a reply. address: " + address);
});
}
计时器会在超时的时候记录错误并强制注销当前consumer。由于reply consumer是一次性的 ,当收到reply的时候,Vert.x会自动对reply consumer调用unregister方法对其进行注销(实现位于EventBusImpl#deliverToHandler方法中),而在注销逻辑中会关闭定时器(参见前面对doUnregister方法的解析);如果超时,那么计时器就会触发,Vert.x会调用sendAsyncResultFailure方法注销当前reply consumer并处理错误。
synchronized的性能问题 大家可能看到为了防止race condition,Vert.x底层大量使用了synchronized关键字(重量级锁)。这会不会影响性能呢?其实,如果开发者遵循Vert.x的线程模型和开发规范(使用Verticle)的话,有些地方的synchronized对应的锁会被优化为 偏向锁 或 轻量级锁 (因为通常都是同一个Event Loop线程获取对应的锁),这样性能总体开销不会太大。当然如果使用Multi-threaded worker verticles就要格外关注性能问题了。。。
总结 我们来简略地总结一下Event Bus的工作原理。当我们调用consumer绑定一个MessageConsumer时,Vert.x会将它保存至Event Bus实例内部的Map中;当我们通过send或publish向对应的地址发送消息的时候,Vert.x会遍历Event Bus中存储consumer的Map,获取与地址相对应的consumer集合,然后根据相应的策略传递并处理消息(send通过轮询策略获取任意一个consumer并将消息传递至consumer中,publish则会将消息传递至所有注册到对应地址的consumer中)。同时,MessageConsumer和MessageProducer这两个接口的实现都具有flow control功能,因此它们也可以用在Pump中。
Event Bus是Vert.x中最为重要的一部分之一,探索Event Bus的源码可以加深我们对Event Bus工作原理的理解。作为开发者,只会使用框架是不够的,能够理解内部的实现原理和精华,并对其进行改进才是更为重要的。本篇文章分析的是Local模式下的Event Bus,下篇文章我们将来探索一下生产环境中更常用的 Clustered Event Bus 的实现原理,敬请期待!