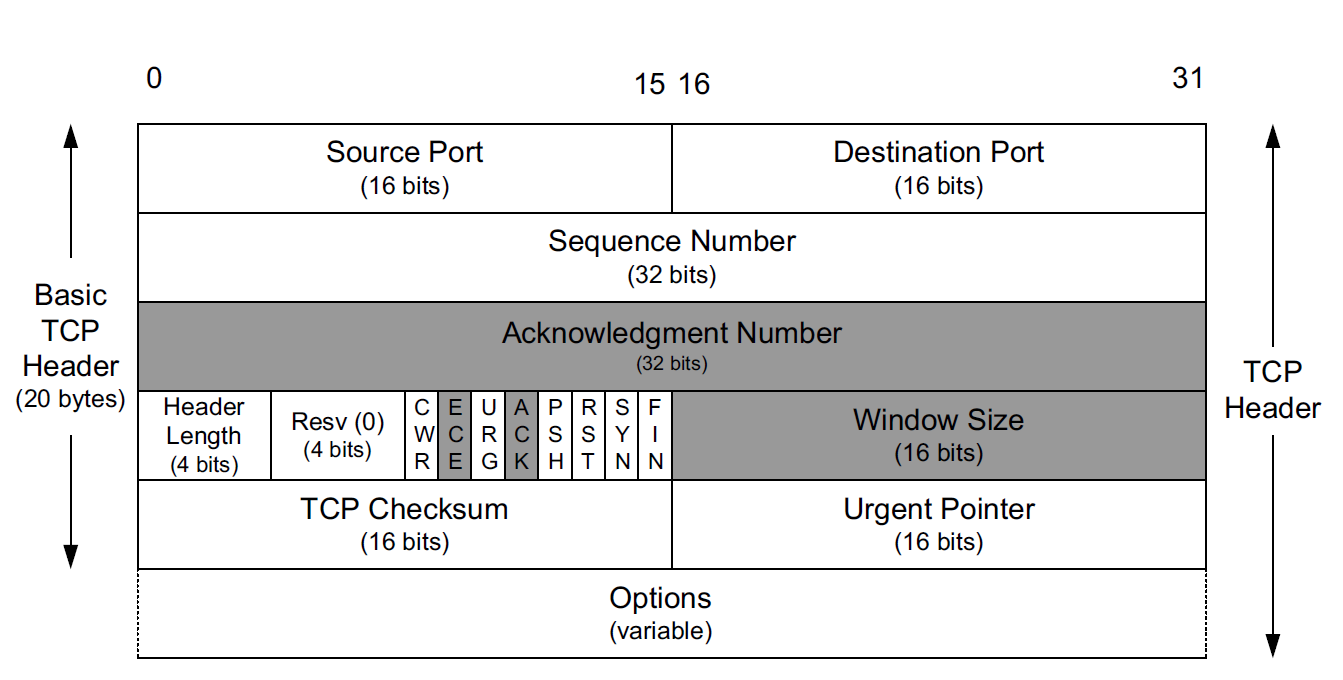
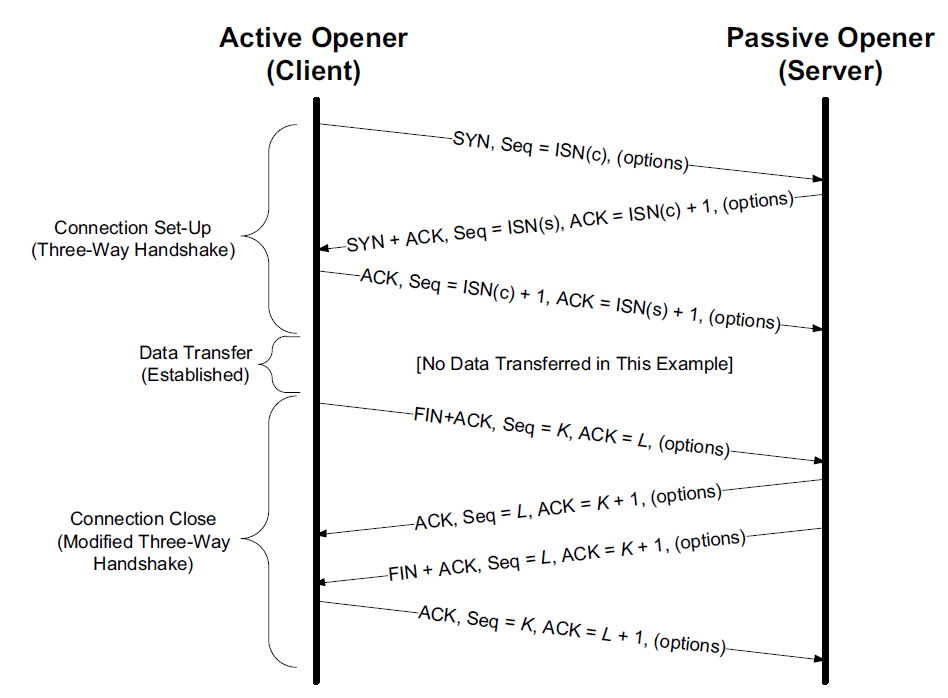
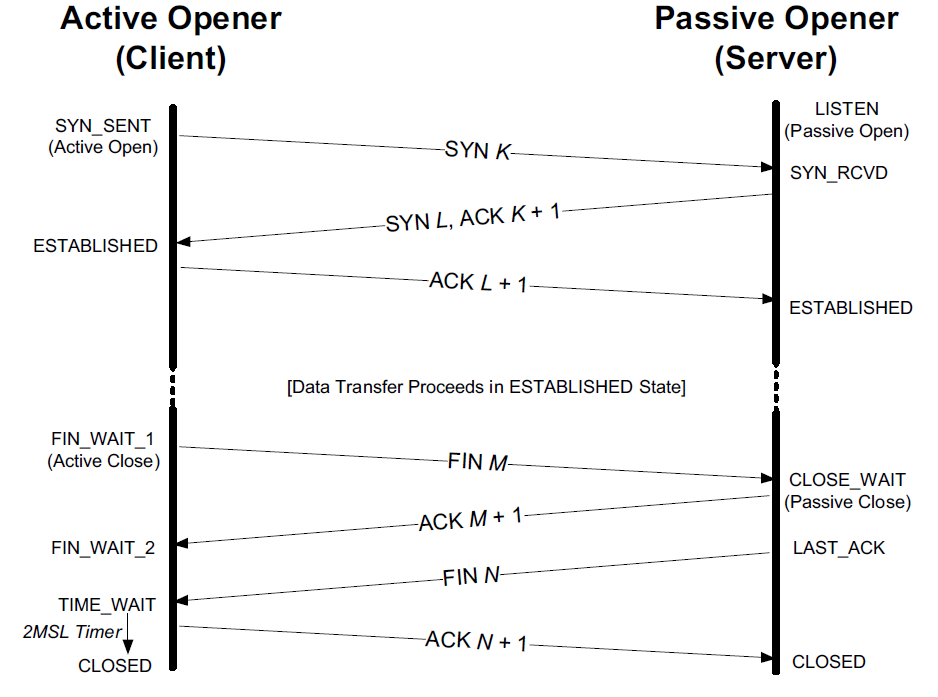
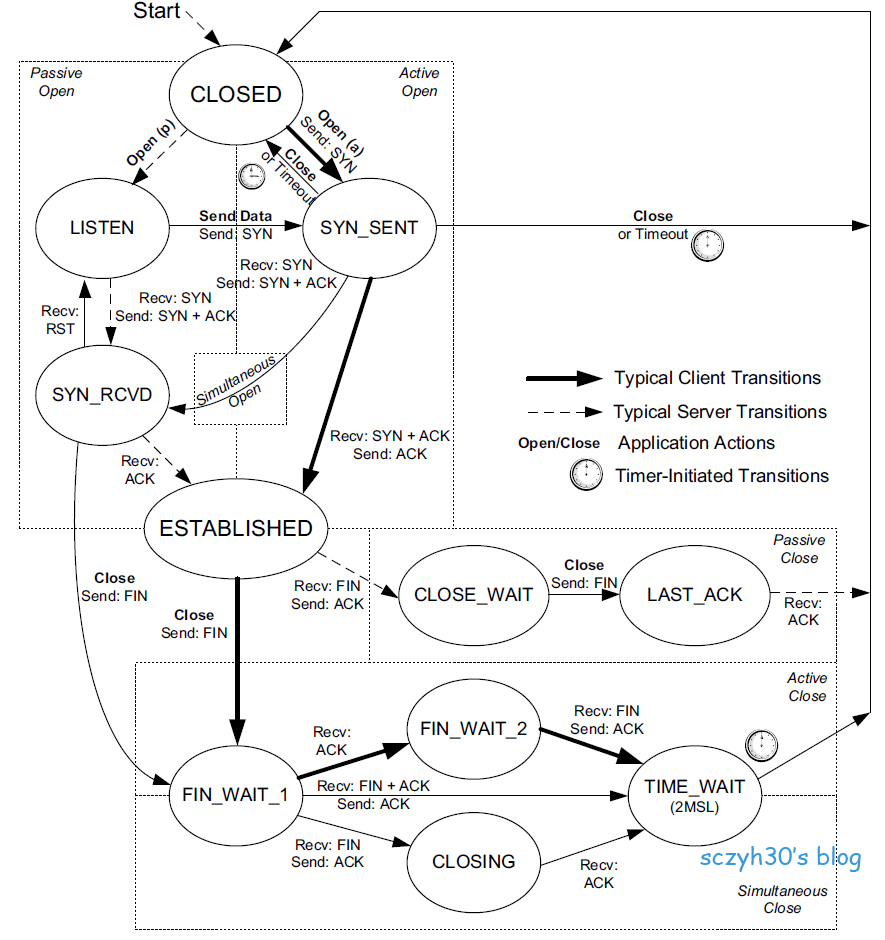
instanceOopDesc 对象头包含两部分信息:Mark Word 和 元数据指针(Klass*):
1
2
3
4
5
volatile markOop _mark;
union _metadata {
Klass* _klass;
narrowKlass _compressed_klass;
} _metadata;
分别来看一下:
Mark Word:instanceOopDesc 中的 _mark 成员,允许压缩。它用于存储对象的运行时记录信息,如哈希值、GC 分代年龄(Age)、锁状态标志(偏向锁、轻量级锁、重量级锁)、线程持有的锁、偏向线程 ID、偏向时间戳等。
元数据指针:instanceOopDesc 中的 _metadata 成员,它是联合体,可以表示未压缩的 Klass 指针(_klass)和压缩的 Klass 指针。对应的 klass 指针指向一个存储类的元数据的 Klass 对象。
下面我们来分析一下,执行 new A() 的时候,JVM native 层里发生了什么。首先,如果这个类没有被加载过,JVM 就会进行类的加载,并在 JVM 内部创建一个 instanceKlass 对象表示这个类的运行时元数据(相当于 Java 层的 Class 对象)。到初始化的时候(执行 invokespecial A::<init>),JVM 就会创建一个 instanceOopDesc 对象表示这个对象的实例,然后进行 Mark Word 的填充,将元数据指针指向 Klass 对象,并填充实例变量。
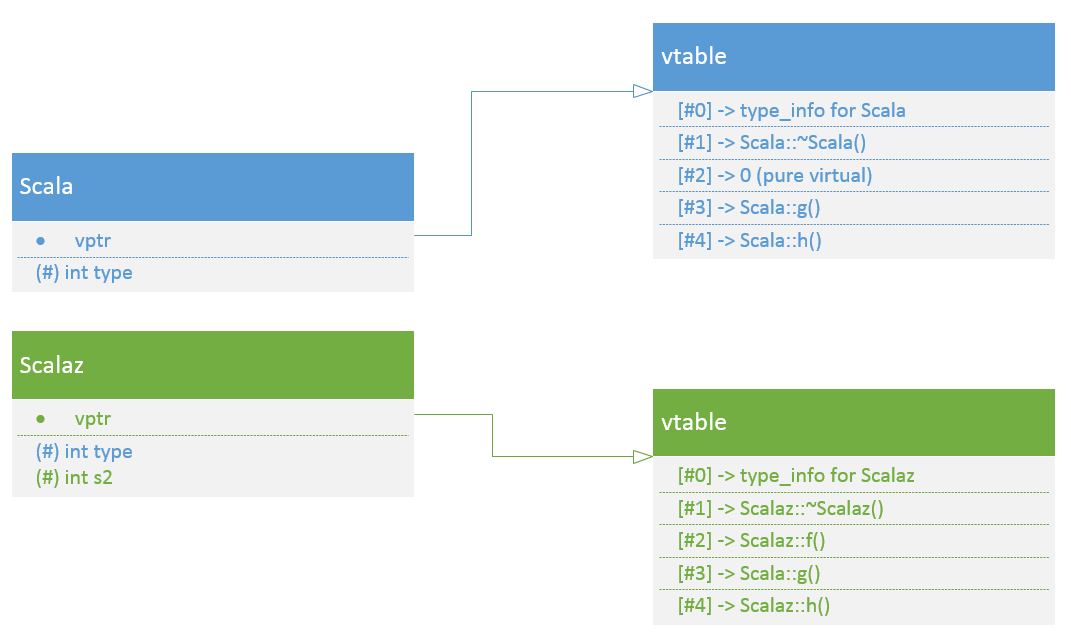
vtable for 'Scala' @ 0x400d70 (subobject @ 0x603010):
[0]: 0x400bf0 <Scalaz::~Scalaz()>
[1]: 0x400c2a <Scalaz::~Scalaz()>
[2]: 0x400c50 <Scalaz::f()>
[3]: 0x400b7a <Scala::g()>
[4]: 0x400c7a <Scalaz::h()>
纯虚函数为什么等于0
在C++标准中,通过使虚函数=0来定义纯虚函数,其含义是在vtbl对应的地方填上0。关于为什么设计纯虚函数,以及纯虚函数为什么为0, The Design and Evolution of C++ 中的描述是:
The curious =0 syntax was chosen over the obvious alternative of introducing a new keyword pure or abstract because at the time I saw no chance of getting a new keyword accepted. Had I suggested pure, Release 2.0 would have shipped without abstract classes. Given a choice between a nicer syntax and abstract classes, I chose abstract classes. Rather than risking delay and incurring the certain fights over pure, I used the tradition C and C++ convention of using 0 to represent “not there.” The =0 syntax fits with my view that a function body is the initializer for a function also with the (simplistic, but usually adequate) view of the set of virtual functions being implemented as a vector of function pointers.