这两天在给Samsara Aquarius的各个Service写分页的时候,设计了一个抽象层,想把一些公共的分页逻辑放在这个trait中,但是被Slick的类型系统折磨了一点时间。。今天粗略看了一下相关的源码,结合这几天遇到的问题,总结一下。因此就把这篇文章作为Prologue吧。。。(Slick的版本为3.1.1)
蛋疼的类型参数 在Slick里面,分页可以通过drop和take函数实现。query.drop(offset).take(n)对应的SQL为LIMIT n, offset。因此在一开始,我设计了一个trait作为分页逻辑的抽象:
1
2
3
4
5
6
7
trait PageDao
def page Future [Int ]
def fetchWithPage Int ): Future [Seq [_]]
}
其中,page函数用于获取总页数,fetchWithPage函数实现分页查询逻辑。
在Slick里,db操作通过db.run(DBIOAction)进行,而每个Query可以通过result函数隐式转换成DBIOAction,因此我们需要给参数中加上Query,以便我们的Service层可以传递不同的Query:
1
2
3
4
5
6
7
trait PageDao
def page Query [_, _, Seq ]): Future [Int ]
def fetchWithPage Query [_, _, Seq ], offset: Int ): Future [Seq [_]]
}
Query[+E, U, C[_]]是一个接受3个类型参数的type constructor,这为后边的蛋疼埋下伏笔。。
好了,接下来,由于我们需要在抽象层进行db操作,因此必须获取db对象,这里我选择继承HasDatabaseConfigProvider[JdbcProfile]:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
trait WithPageProvider extends HasDatabaseConfigProvider [JdbcProfile ] with PageDao
import driver.api._
val withQueryByPage =
(query: slick.lifted.Query [_, _, _], offset: Int ) =>
query.drop(offset).take(LIMIT_PAGE )
def page Query [_, _, _]): Future [Int ] = {
db.run(query.length.result) map { all =>
val p = all % LIMIT_PAGE == 0
if (p) all / LIMIT_PAGE
else (all / LIMIT_PAGE ) + 1
} recover {
case ex: Exception => 0
}
}
def fetchWithPage Query [_, _, _], offset: Int ): Future [Seq [_]] = {
db.run(withQueryByPage(query, offset).result)
}
}
嗯。。逻辑很快写好了,一切似乎都是OK的,下面在业务层中调用一下:
1
2
def fetchWithPage Int ): Future [Seq [(Category , Int )]] =
super .fetchWithPage(categoriesCompiled, offset)
很快,远方就传来了IDE提示GG的声音。。。提示:Expression of type Future[Seq[_]] doesn't conform to expected type Future[Seq[(Category, Int)]]。
嗯。。。看来是必须具化Seq的type parameter了。。那么就给trait里的fetchWithPage加个type parameter吧。。下面就陷入了苦逼的Slick类型系统初探过程——Slick在run、result的过程中,如何从一个原始的Query[+E, U, C[_]]转化为最终的Future[Seq[R]]?也就是说Query的这几个type parameters该取什么类型?想解决这个问题,只能看Slick的源码了。。首先从run函数出发,看看Future是怎么产生的:
1
2
final def run R ](a: DBIOAction [R , NoStream , Nothing ]): Future [R ] = runInternal(a, false )
可以看到,最后返回Future的类型参数是DBIOAction[R, NoStream, Nothing]的第一个类型参数R。接着我们看一下DBIOAction的定义:
1
sealed trait DBIOAction [+R , +S <: NoStream , -E <: Effect ] extends Dumpable
嗯,看到这里,似乎明白了什么。。然后再看一下Query的定义:
1
2
3
sealed trait QueryBase [T ] extends Rep [T ]
sealed abstract class Query [+E , U , C [_]] extends QueryBase [C [U ]]
可以看到Query[+E, U, C[_]]继承了QueryBase[C[U]],然而注释里完全没有这三个type parameters的含义,所以就瞎猜。。注释里提到计算结果代表一个集合类型,如Rep[Seq[T]],而QueryBase[T]又继承了Rep[T],所以很容易想到Query第三个类型参数为Seq。然而一开始没有看到后边的[C[U]],又因为DBIOAction中返回类型为第一个类型参数R,因此就错误地把这里的返回类型想成了第一个类型参数E(还是协变的,很迷惑人)。于是把fetchWithPage改成了这样:
1
def fetchWithPage R ](query: slick.lifted.Query [R , _, Seq ], offset: Int ): Future [Seq [R ]]
仍然在报错,这次成了Expression of type Future[Seq[Any]] doesn't conform to expected type Future[Seq[R]]。
这时候提示就比较明显了,既然第一个类型参数已经限定为R,而返回值还为Future[Seq[Any]],那么很容易就会联想到当前为_的类型参数有猫腻,即Query[+E, U, C[_]]中的U。这时候再看到后边继承的QueryBase[C[U]],一切都一目了然了。这里的QueryBase[C[U]]是一个higher-kinded type,既然我们将C设为Seq,那么很容易想到C[U]其实就是对应着Seq[Result],那么我们的R参数应该放在Query的第二个类型参数U上。改一下发现,一切都正常了:1
2
3
def fetchWithPage R ](query: slick.lifted.Query [_, R , Seq ], offset: Int ): Future [Seq [R ]] = {
db.run(withQueryByPage(query, offset).result)
}
寻根溯源 问题解决了,但Query[+E, U, C[_]]里那个+E实在是很迷惑人,于是就继续探究了探究它到底是什么玩意。注释里没写,那就从Query的实现中找吧。。在TableQuery的定义中有:1
2
3
4
5
6
7
8
9
10
class TableQuery [E <: AbstractTable [_]](cons: Tag => E ) extends Query [E , E #TableElementType , Seq ]
abstract class AbstractTable [T ](val tableTag: Tag , val schemaName: Option [String ], val tableName: String ) extends Rep [T ]
type TableElementType
}
E需要是AbstractTable[_]的子类,而我们在定义表的映射的时候都是继承了Table[_]类,因此可以确定E就是查询的类型所对应的Table类(比如ArticleTable)。
另外一个值的探究的地方就是那个result函数是如何将一个Query转化为DBIOAction的。蛋疼的地方在于这个转换是隐式的(相当于实现了Typeclass Pattern),因此追踪如何转换的比较困难。好在写代码的时候发现,如果不导入driver.api._的话,就会找不到result函数,因此可以从这里入手。跳转到api的源码:
1
val api: API = new API {}
那么秘密应该就藏在JdbcProfile#API类里了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
trait API extends LowPriorityAPI with super .API with ImplicitColumnTypes
type FastPath [T ] JdbcFastPath [T ]
type SimpleDBIO [+R ] SimpleJdbcAction [R ]
val SimpleDBIO = SimpleJdbcAction
implicit def jdbcFastPathExtensionMethods T , P ](mp: MappedProjection [T , P ]) = new JdbcFastPathExtensionMethods [T , P ](mp)
implicit def queryDeleteActionExtensionMethods C [_]](q: Query [_ <: RelationalProfile #Table [_], _, C ]): DeleteActionExtensionMethods =
createDeleteActionExtensionMethods(deleteCompiler.run(q.toNode).tree, ())
implicit def runnableCompiledDeleteActionExtensionMethods RU , C [_]](c: RunnableCompiled [_ <: Query [_, _, C ], C [RU ]]): DeleteActionExtensionMethods =
createDeleteActionExtensionMethods(c.compiledDelete, c.param)
implicit def runnableCompiledUpdateActionExtensionMethods RU , C [_]](c: RunnableCompiled [_ <: Query [_, _, C ], C [RU ]]): UpdateActionExtensionMethods [RU ] =
createUpdateActionExtensionMethods(c.compiledUpdate, c.param)
implicit def jdbcActionExtensionMethods E <: Effect , R , S <: NoStream ](a: DBIOAction [R , S , E ]): JdbcActionExtensionMethods [E , R , S ] =
new JdbcActionExtensionMethods [E , R , S ](a)
implicit def actionBasedSQLInterpolation StringContext ) = new ActionBasedSQLInterpolation (s)
}
这里面存在这样的继承关系(简化过后的):JdbcProfile#API <:< RelationalProfile#API <:< BasicProfile#API。
再看RelationalProfile中的API类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
trait API extends super .API with ImplicitColumnTypes
type Table [T ] Table [T ]
type Sequence [T ] Sequence [T ]
val Sequence = driver.Sequence
type ColumnType [T ] ColumnType [T ]
type BaseColumnType [T ] BaseColumnType [T ]
val MappedColumnType = driver.MappedColumnType
@deprecated ("Use an explicit conversion to an Option column with `.?`" , "3.0" )
implicit def columnToOptionColumn T : BaseTypedType ](c: Rep [T ]): Rep [Option [T ]] = c.?
implicit def valueToConstColumn T : TypedType ](v: T ) = new LiteralColumn [T ](v)
implicit def columnToOrdered T : TypedType ](c: Rep [T ]): ColumnOrdered [T ] = ColumnOrdered [T ](c, Ordering ())
implicit def tableQueryToTableQueryExtensionMethods T <: RelationalProfile #Table [_], U ](q: Query [T , U , Seq ] with TableQuery [T ]) =
new TableQueryExtensionMethods [T , U ](q)
implicit def streamableCompiledInsertActionExtensionMethods EU ](c: StreamableCompiled [_, _, EU ]): InsertActionExtensionMethods [EU ] = createInsertActionExtensionMethods[EU ](c.compiledInsert.asInstanceOf[CompiledInsert ])
implicit def queryInsertActionExtensionMethods U , C [_]](q: Query [_, U , C ]) = createInsertActionExtensionMethods[U ](compileInsert(q.toNode))
implicit def schemaActionExtensionMethods SchemaDescription ): SchemaActionExtensionMethods = createSchemaActionExtensionMethods(sd)
}
再看BasicProfile中的API类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
trait API extends Aliases with ExtensionMethodConversions
type Database Backend #Database
val Database = backend.Database
type Session Backend #Session
type SlickException SlickException
implicit val slickDriver: driver.type = driver
@inline implicit final def anyToToShapedValue T ](value: T ) = new ToShapedValue [T ](value)
implicit def repQueryActionExtensionMethods U ](rep: Rep [U ]): QueryActionExtensionMethods [U , NoStream ] =
createQueryActionExtensionMethods[U , NoStream ](queryCompiler.run(rep.toNode).tree, ())
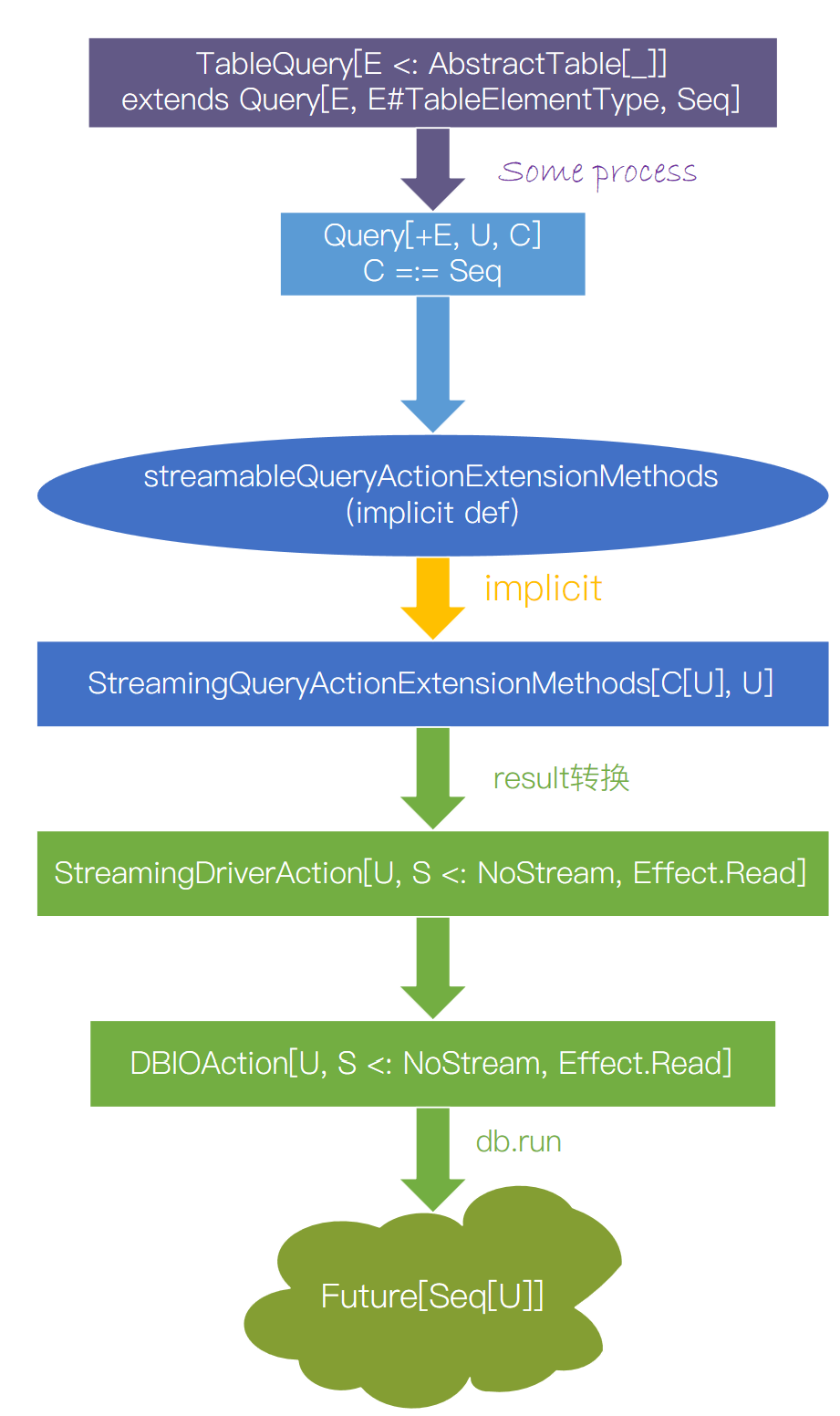
implicit def streamableQueryActionExtensionMethods U , C [_]](q: Query [_,U , C ]): StreamingQueryActionExtensionMethods [C [U ], U ] =
createStreamingQueryActionExtensionMethods[C [U ], U ](queryCompiler.run(q.toNode).tree, ())
implicit def runnableCompiledQueryActionExtensionMethods RU ](c: RunnableCompiled [_, RU ]): QueryActionExtensionMethods [RU , NoStream ] =
createQueryActionExtensionMethods[RU , NoStream ](c.compiledQuery, c.param)
implicit def streamableCompiledQueryActionExtensionMethods RU , EU ](c: StreamableCompiled [_, RU , EU ]): StreamingQueryActionExtensionMethods [RU , EU ] =
createStreamingQueryActionExtensionMethods[RU , EU ](c.compiledQuery, c.param)
implicit def streamableAppliedCompiledFunctionActionExtensionMethods R , RU , EU , C [_]](c: AppliedCompiledFunction [_, Query [R , EU , C ], RU ]): StreamingQueryActionExtensionMethods [RU , EU ] =
createStreamingQueryActionExtensionMethods[RU , EU ](c.compiledQuery, c.param)
implicit def recordQueryActionExtensionMethods M , R ](q: M )(implicit shape: Shape [_ <: FlatShapeLevel , M , R , _]): QueryActionExtensionMethods [R , NoStream ] =
createQueryActionExtensionMethods[R , NoStream ](queryCompiler.run(shape.toNode(q)).tree, ())
}
如此多的implicit转换,可以将Query和CompiledQuery转换成各种QueryActionExtensionMethods。那么我们再来看result的源码,看看它是不是在某个QueryActionExtensionMethods类里:
1
2
3
4
class StreamingQueryActionExtensionMethodsImpl [R , T ](tree: Node , param: Any ) extends QueryActionExtensionMethodsImpl [R , Streaming [T ]](tree, param ) with super .StreamingQueryActionExtensionMethodsImpl [R , T ]
override def result StreamingDriverAction [R , T , Effect .Read ] = super .result.asInstanceOf[StreamingDriverAction [R , T , Effect .Read ]]
}
果然!result方法存在于这个QueryActionExtensionMethods类里,而且Query可以通过上述API隐式转换为QueryActionExtensionMethods。这个类好混乱,继承了两个trait,还没注释(这一点最蛋疼了,直接看源码估计无解)。再往它的父类找:
1
2
3
4
5
6
7
8
trait QueryActionExtensionMethodsImpl [R , S <: NoStream ]
def result DriverAction [R , S , Effect .Read ]
}
trait StreamingQueryActionExtensionMethodsImpl [R , T ] extends QueryActionExtensionMethodsImpl [R , Streaming [T ]]
def result StreamingDriverAction [R , T , Effect .Read ]
}
它们是最基本的QueryActionExtensionMethods,即查询操作。
到此为止,我们终于搞明白了一个数据库查询过程中从Query经过implicit的result转换成DBIOAction,再进行db.run得到Future异步结果的类型转换的过程。我做了一张图来总结这个过程: