以前只知道 ThreadLocal 的大致思路,没有去深入研究。今天读了读源码,果然博大精深~
ThreadLocal 提供了线程本地变量,它可以保证访问到的变量属于当前线程,每个线程都保存有一个变量副本,每个线程的变量都不同,而同一个线程在任何时候访问这个本地变量的结果都是一致的。当此线程结束生命周期时,所有的线程本地实例都会被 GC。ThreadLocal 相当于提供了一种线程隔离,将变量与线程相绑定。ThreadLocal 通常定义为 private static 类型。
假如让我们来实现一个变量与线程相绑定的功能,我们可以很容易地想到用HashMap来实现,Thread作为key,变量作为value。事实上,JDK 中确实使用了类似 Map 的结构存储变量,但不是像我们想的那样。下面我们来探究OpenJDK 1.8中ThreadLocal的实现。
初探 ThreadLocal 我们从 ThreadLocal 的几个成员变量入手:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
private final int threadLocalHashCode = nextHashCode();
* The next hash code to be given out. Updated atomically. Starts at
* zero.
*/
private static AtomicInteger nextHashCode =
new AtomicInteger();
* The difference between successively generated hash codes - turns
* implicit sequential thread-local IDs into near-optimally spread
* multiplicative hash values for power-of-two-sized tables.
*/
private static final int HASH_INCREMENT = 0x61c88647 ;
* Returns the next hash code.
*/
private static int nextHashCode ()
return nextHashCode.getAndAdd(HASH_INCREMENT);
}
ThreadLocal 通过 threadLocalHashCode 来标识每一个 ThreadLocal 的唯一性。threadLocalHashCode 通过 CAS 操作进行更新,每次 hash 操作的增量为 0x61c88647 (这个数的原理没有探究)。
再看 set 方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
* Sets the current thread's copy of this thread-local variable
* to the specified value. Most subclasses will have no need to
* override this method, relying solely on the {@link #initialValue}
* method to set the values of thread-locals.
*
* @param value the value to be stored in the current thread's copy of
* this thread-local.
*/
public void set (T value)
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null )
map.set(this , value);
else
createMap(t, value);
}
可以看到通过Thread.currentThread()方法获取了当前的线程引用,并传给了getMap(Thread)方法获取一个ThreadLocalMap的实例。我们继续跟进getMap(Thread)方法:1
2
3
ThreadLocalMap getMap (Thread t) {
return t.threadLocals;
}
可以看到getMap(Thread)方法直接返回Thread实例的成员变量threadLocals。它的定义在Thread内部,访问级别为package级别:
1
2
3
* by the ThreadLocal class. */
ThreadLocal.ThreadLocalMap threadLocals = null ;
到了这里,我们可以看出,每个Thread里面都有一个ThreadLocal.ThreadLocalMap成员变量,也就是说每个线程通过ThreadLocal.ThreadLocalMap与ThreadLocal相绑定,这样可以确保每个线程访问到的thread-local variable都是本线程的。
我们往下继续分析。获取了ThreadLocalMap实例以后,如果它不为空则调用ThreadLocalMap.ThreadLocalMap#set方法设值;若为空则调用ThreadLocal#createMap方法new一个ThreadLocalMap实例并赋给Thread.threadLocals。
ThreadLocal#createMap方法的源码如下:1
2
3
void createMap (Thread t, T firstValue)
t.threadLocals = new ThreadLocalMap(this , firstValue);
}
下面我们探究一下 ThreadLocalMap 的实现。
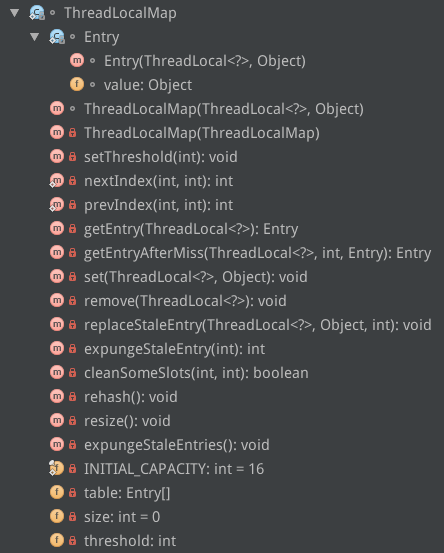
ThreadLocalMap ThreadLocalMap 是 ThreadLocal 的静态内部类,它的结构如下:
可以看到ThreadLocalMap有一个常量和三个成员变量:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
* The initial capacity -- MUST be a power of two.
*/
private static final int INITIAL_CAPACITY = 16 ;
* The table, resized as necessary.
* table.length MUST always be a power of two.
*/
private Entry[] table;
* The number of entries in the table.
*/
private int size = 0 ;
* The next size value at which to resize.
*/
private int threshold;
其中 INITIAL_CAPACITY代表这个Map的初始容量;table 是一个Entry 类型的数组,用于存储数据;size 代表表中的存储数目; threshold 代表需要扩容时对应 size 的阈值。
Entry 类是 ThreadLocalMap 的静态内部类,用于存储数据。它的源码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
* The entries in this hash map extend WeakReference, using
* its main ref field as the key (which is always a
* ThreadLocal object). Note that null keys (i.e. entry.get()
* == null) mean that the key is no longer referenced, so the
* entry can be expunged from table. Such entries are referred to
* as "stale entries" in the code that follows.
*/
static class Entry extends WeakReference <ThreadLocal <?>>
Object value;
Entry(ThreadLocal<?> k, Object v) {
super (k);
value = v;
}
}
Entry类继承了WeakReference<ThreadLocal<?>>,即每个Entry对象都有一个ThreadLocal的弱引用(作为key),这是为了防止内存泄露。一旦线程结束,key变为一个不可达的对象,这个Entry就可以被GC了。
ThreadLocalMap类有两个构造函数,其中常用的是ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue):1
2
3
4
5
6
7
8
9
10
11
12
* Construct a new map initially containing (firstKey, firstValue).
* ThreadLocalMaps are constructed lazily, so we only create
* one when we have at least one entry to put in it.
*/
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
table = new Entry[INITIAL_CAPACITY];
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1 );
table[i] = new Entry(firstKey, firstValue);
size = 1 ;
setThreshold(INITIAL_CAPACITY);
}
构造函数的第一个参数就是本ThreadLocal实例(this),第二个参数就是要保存的线程本地变量。构造函数首先创建一个长度为16的Entry数组,然后计算出firstKey对应的哈希值,然后存储到table中,并设置size和threshold。
注意一个细节,计算hash的时候里面采用了hashCode & (size - 1)的算法,这相当于取模运算hashCode % size的一个更高效的实现(和HashMap中的思路相同)。正是因为这种算法,我们要求size必须是 2的指数 ,因为这可以使得hash发生冲突的次数减小。
接下来我们来看ThreadLocalMap#set方法的实现:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
* Set the value associated with key.
*
* @param key the thread local object
* @param value the value to be set
*/
private void set (ThreadLocal<?> key, Object value)
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1 );
for (Entry e = tab[i];
e != null ;
e = tab[i = nextIndex(i, len)]) {
ThreadLocal<?> k = e.get();
if (k == key) {
e.value = value;
return ;
}
if (k == null ) {
replaceStaleEntry(key, value, i);
return ;
}
}
tab[i] = new Entry(key, value);
int sz = ++size;
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}
如果冲突了,就会通过nextIndex方法再次计算哈希值:1
2
3
4
5
6
* Increment i modulo len.
*/
private static int nextIndex (int i, int len)
return ((i + 1 < len) ? i + 1 : 0 );
}
到这里,我们看到 ThreadLocalMap 解决冲突的方法是 线性探测法 (不断加 1),而不是 HashMap 的 链地址法 ,这一点也能从 Entry 的结构上推断出来。
如果entry里对应的key为null的话,表明此entry为staled entry,就将其替换为当前的key和value:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
* Replace a stale entry encountered during a set operation
* with an entry for the specified key. The value passed in
* the value parameter is stored in the entry, whether or not
* an entry already exists for the specified key.
*
* As a side effect, this method expunges all stale entries in the
* "run" containing the stale entry. (A run is a sequence of entries
* between two null slots.)
*
* @param key the key
* @param value the value to be associated with key
* @param staleSlot index of the first stale entry encountered while
* searching for key.
*/
private void replaceStaleEntry (ThreadLocal<?> key, Object value,
int staleSlot) {
Entry[] tab = table;
int len = tab.length;
Entry e;
int slotToExpunge = staleSlot;
for (int i = prevIndex(staleSlot, len);
(e = tab[i]) != null ;
i = prevIndex(i, len))
if (e.get() == null )
slotToExpunge = i;
for (int i = nextIndex(staleSlot, len);
(e = tab[i]) != null ;
i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
if (k == key) {
e.value = value;
tab[i] = tab[staleSlot];
tab[staleSlot] = e;
if (slotToExpunge == staleSlot)
slotToExpunge = i;
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
return ;
}
if (k == null && slotToExpunge == staleSlot)
slotToExpunge = i;
}
tab[staleSlot].value = null ;
tab[staleSlot] = new Entry(key, value);
if (slotToExpunge != staleSlot)
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
}
具体实现不再深究,这替换过程里面也进行了不少的垃圾清理动作以防止引用关系存在而导致的内存泄露。
若是经历了上面步骤没有命中hash,也没有发现无用的Entry,set方法就会创建一个新的Entry,并会进行启发式的垃圾清理 ,用于清理无用的Entry。主要通过cleanSomeSlots方法进行清理(清理的时机通常为添加新元素或另一个无用的元素被回收时。参见注释):1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
* Heuristically scan some cells looking for stale entries.
* This is invoked when either a new element is added, or
* another stale one has been expunged. It performs a
* logarithmic number of scans, as a balance between no
* scanning (fast but retains garbage) and a number of scans
* proportional to number of elements, that would find all
* garbage but would cause some insertions to take O(n) time.
*
* @param i a position known NOT to hold a stale entry. The
* scan starts at the element after i.
*
* @param n scan control: {@code log2(n)} cells are scanned,
* unless a stale entry is found, in which case
* {@code log2(table.length)-1} additional cells are scanned.
* When called from insertions, this parameter is the number
* of elements, but when from replaceStaleEntry, it is the
* table length. (Note: all this could be changed to be either
* more or less aggressive by weighting n instead of just
* using straight log n. But this version is simple, fast, and
* seems to work well.)
*
* @return true if any stale entries have been removed.
*/
private boolean cleanSomeSlots (int i, int n)
boolean removed = false ;
Entry[] tab = table;
int len = tab.length;
do {
i = nextIndex(i, len);
Entry e = tab[i];
if (e != null && e.get() == null ) {
n = len;
removed = true ;
i = expungeStaleEntry(i);
}
} while ( (n >>>= 1 ) != 0 );
return removed;
}
一旦发现一个位置对应的 Entry 所持有的 ThreadLocal 弱引用为null,就会把此位置当做 staleSlot 并调用 expungeStaleEntry 方法进行整理 (rehashing) 的操作:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
* Expunge a stale entry by rehashing any possibly colliding entries
* lying between staleSlot and the next null slot. This also expunges
* any other stale entries encountered before the trailing null. See
* Knuth, Section 6.4
*
* @param staleSlot index of slot known to have null key
* @return the index of the next null slot after staleSlot
* (all between staleSlot and this slot will have been checked
* for expunging).
*/
private int expungeStaleEntry (int staleSlot)
Entry[] tab = table;
int len = tab.length;
tab[staleSlot].value = null ;
tab[staleSlot] = null ;
size--;
Entry e;
int i;
for (i = nextIndex(staleSlot, len);
(e = tab[i]) != null ;
i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
if (k == null ) {
e.value = null ;
tab[i] = null ;
size--;
} else {
int h = k.threadLocalHashCode & (len - 1 );
if (h != i) {
tab[i] = null ;
while (tab[h] != null )
h = nextIndex(h, len);
tab[h] = e;
}
}
}
return i;
}
只要没有清理任何的 stale entries 并且 size 达到阈值的时候(即 table 已满,所有元素都可用),都会触发rehashing:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
* Re-pack and/or re-size the table. First scan the entire
* table removing stale entries. If this doesn't sufficiently
* shrink the size of the table, double the table size.
*/
private void rehash ()
expungeStaleEntries();
if (size >= threshold - threshold / 4 )
resize();
}
* Expunge all stale entries in the table.
*/
private void expungeStaleEntries ()
Entry[] tab = table;
int len = tab.length;
for (int j = 0 ; j < len; j++) {
Entry e = tab[j];
if (e != null && e.get() == null )
expungeStaleEntry(j);
}
}
rehash 操作会执行一次全表的扫描清理工作,并在 size 大于等于 threshold 的四分之三时进行 resize。但注意在 setThreshold 的时候又取了三分之二:
1
2
3
4
5
6
* Set the resize threshold to maintain at worst a 2/3 load factor.
*/
private void setThreshold (int len)
threshold = len * 2 / 3 ;
}
因此 ThreadLocalMap 的实际 load factor 为 3/4 * 2/3 = 0.5。
我们继续看 getEntry 的源码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
* Get the entry associated with key. This method
* itself handles only the fast path: a direct hit of existing
* key. It otherwise relays to getEntryAfterMiss. This is
* designed to maximize performance for direct hits, in part
* by making this method readily inlinable.
*
* @param key the thread local object
* @return the entry associated with key, or null if no such
*/
private Entry getEntry (ThreadLocal<?> key)
int i = key.threadLocalHashCode & (table.length - 1 );
Entry e = table[i];
if (e != null && e.get() == key)
return e;
else
return getEntryAfterMiss(key, i, e);
}
* Version of getEntry method for use when key is not found in
* its direct hash slot.
*
* @param key the thread local object
* @param i the table index for key's hash code
* @param e the entry at table[i]
* @return the entry associated with key, or null if no such
*/
private Entry getEntryAfterMiss (ThreadLocal<?> key, int i, Entry e)
Entry[] tab = table;
int len = tab.length;
while (e != null ) {
ThreadLocal<?> k = e.get();
if (k == key)
return e;
if (k == null )
expungeStaleEntry(i);
else
i = nextIndex(i, len);
e = tab[i];
}
return null ;
}
逻辑很简单,hash以后如果是ThreadLocal对应的Entry就返回,否则调用getEntryAfterMiss方法,根据线性探测法继续查找,直到找到或对应entry为null,并返回。
ThreadLocal的get方法就是调用了ThreadLocalMap的getEntry方法:1
2
3
4
5
6
7
8
9
10
11
12
13
public T get ()
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null ) {
ThreadLocalMap.Entry e = map.getEntry(this );
if (e != null ) {
@SuppressWarnings ("unchecked" )
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
remove 方法的思想类似,直接放源码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
* Remove the entry for key.
*/
private void remove (ThreadLocal<?> key)
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1 );
for (Entry e = tab[i];
e != null ;
e = tab[i = nextIndex(i, len)]) {
if (e.get() == key) {
e.clear();
expungeStaleEntry(i);
return ;
}
}
}
remove的时候同样也会调用expungeStaleEntry方法执行清理工作。
总结 每个 Thread 里都含有一个 ThreadLocalMap 的成员变量,这种机制将 ThreadLocal 和线程巧妙地绑定在了一起,即可以保证无用的 ThreadLocal 被及时回收,不会造成内存泄露,又可以提升性能。假如我们把 ThreadLocalMap 做成一个 Map<t extends Thread, ?> 类型的 Map,那么它存储的东西将会非常多(相当于一张全局线程本地变量表),这样的情况下用线性探测法解决哈希冲突的问题效率会非常差。而 JDK 里的这种利用 ThreadLocal 作为 key,再将 ThreadLocalMap 与线程相绑定的实现,完美地解决了这个问题。
总结一下什么时候无用的 Entry 会被清理:
Thread 结束的时候
插入元素时,发现 staled entry,则会进行替换并清理
插入元素时,ThreadLocalMap 的 size 达到 threshold,并且没有任何 staled entries 的时候,会调用 rehash 方法清理并扩容
调用 ThreadLocalMap 的 remove 方法或set(null) 时
尽管不会造成内存泄露,但是可以看到无用的 Entry 只会在以上四种情况下才会被清理,这就可能导致一些 Entry 虽然无用但还占内存的情况。因此,我们在使用完 ThreadLocal 后一定要remove一下,保证及时回收掉无用的 Entry。
特别地,当应用线程池的时候,由于线程池的线程一般会复用,Thread 不结束,这时候用完更需要 remove 了。
总的来说,对于多线程资源共享的问题,同步机制采用了 以时间换空间 的方式,而 ThreadLocal 则采用了 以空间换时间 的方式。前者仅提供一份变量,让不同的线程排队访问;而后者为每一个线程都提供了一份变量,因此可以同时访问而互不影响。
应用 应用太多了,举个 Spring 的例子。Spring 对一些 Bean 中的成员变量采用 ThreadLocal 进行处理,让它们可以成为线程安全的。举个例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
package org.springframework.web.context.request;
public abstract class RequestContextHolder
private static final boolean jsfPresent =
ClassUtils.isPresent("javax.faces.context.FacesContext" , RequestContextHolder.class.getClassLoader());
private static final ThreadLocal<RequestAttributes> requestAttributesHolder =
new NamedThreadLocal<RequestAttributes>("Request attributes" );
private static final ThreadLocal<RequestAttributes> inheritableRequestAttributesHolder =
new NamedInheritableThreadLocal<RequestAttributes>("Request context" );
}
再比如 Spring MVC 中的 Controller 默认是 singleton 的,因此如果 Controller 或其对应的 Service 里存在非静态成员变量的话,并发访问就会出现 race condition 问题,这也可以通过 ThreadLocal 解决。